




I. Présentation▲
VMware vCenter Operations manager est un produit VMware qui via des fonctions d'analyse automatique du datacenter virtuel permet la gestion automatisée des opérations sur l'infrastructure virtuelle VMware. Il permet en outre d'avoir une vision globale de « l'état de santé » du datacenter via la présentation de compteurs directement exploitables par les administrateurs pour garantir un niveau d'utilisation des ressources optimale et une qualité de service améliorée.
Ses principaux avantages sont les suivants :
- une qualité de service améliorée ;
- une amélioration du travail collaboratif entre les différentes équipes ;
- une économie via une rationalisation des ressources ;
- un monitoring complet de l'environnement virtuel ;
- le respect des règles et règlements informatiques en vigueur.
II. Architecture▲
vCenter operations manager est une vApp (au format OVF) composée de deux machines virtuelles. Attachons-nous maintenant à décrire l'architecture de ce produit.
II-A. UI VM▲
La machine virtuelle UI correspond comme son nom l'indique à l'interface graphique de vCenter Ops Manager. Elle héberge une application Web qui permet de présenter les résultats des calculs de vCenter Operations Manager sous forme de Dashboards, scores ou badges. Cette application Web est elle-même composée de trois sous-applications distinctes :
- vSphere Web Application : comprend différentes vues et résumés de l'architecture virtuelle vSphere ;
- Enterprise Web Application : interface customisable par l'utilisateur (disponible à partir de la licence entreprise) et permet d'afficher une vue de toute l'organisation ;
- Administration Web Application : permet de planifier la maintenance et la gestion (administration) de vCenter Operations Manager.
II-B. Analytics VM▲
Cette VM collecte et stocke les données acquises via vCenter, vCenter Operations Manager et d'autres third-parties, ces données sont stockées dans une BD. Les composants de cette VM sont les suivants :
- Capacity and Performance Analytics : contrôle des métriques en temps réel pour détecter les anomalies et mettre à jour le score de l'état de santé et générer des alertes si nécessaire ;
- Capacity Collector : collecte les métriques ;
- FileSystem Database : stocke les métriques collectées ;
- Postgres DB : stocke les autres données (les objets, relations, évènements, alarmes…).
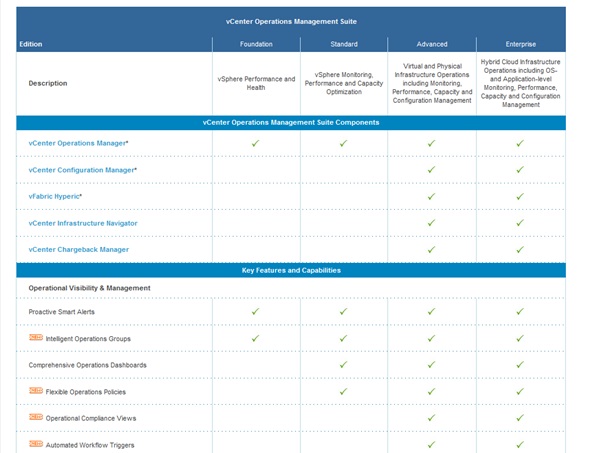
III. Licensing▲
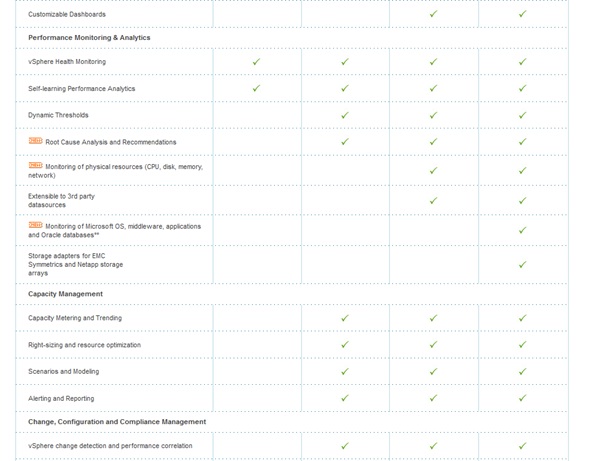
vCenter Operations manager se présente sous la forme d'une appliance virtuelle utilisée pour monitorer l'état de santé, les ressources et la capacité de l'environnement virtuel. Ce produit est disponible en plusieurs éditions (niveau de licence) qui permettent chacune plus ou moins de fonctionnalités comme récapitulé dans le tableau ci-dessous :

IV. Prérequis▲
Les prérequis nécessaires au déploiement de vCenter Operations Manager sont les suivants :

V. Configuration réseau▲
Avant de déployer VMware vCenter Operations Manager, il faut effectuer des actions de configuration réseau au niveau du vCenter.
Pour cela, suivre la procédure suivante.
Ouvrir un vSphere Client, puis se connecter au vCenter et se rendre dans la vue Inventory puis Networking.

Sélectionner l'élément de type Datacenter, puis cliquer sur l'onglet IP Pools.

Cliquer sur Add.
Sélectionner l'onglet IPv4.
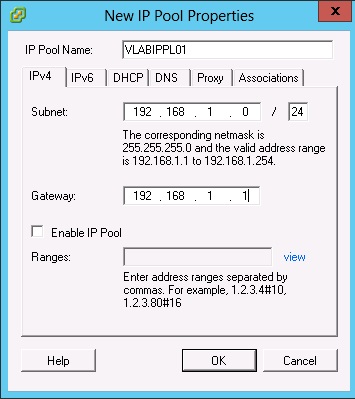
Renseigner un nom pour le pool IP, un subnet et une gateway.
Ne pas cocher la case Enable IP Pool et ne spécifier aucun range.
Cliquer ensuite sur l'onglet DHCP.

Cocher la case correspondante si un DHCP est présent sur le réseau.
Puis cliquer sur l'onglet DNS.

Renseigner les options DNS, puis cliquer sur l'onglet Associations.

Sélectionner le/les réseaux pouvant utiliser ce pool IP.
Pour terminer, cliquer sur OK.
VI. Déploiement▲
Pour déployer vCenter Operations Manager, commencer par le télécharger sur le site de VMware.
Puis, en ouvrant un vSphere Client, cliquer sur File, puis Deploy OVF Template.
L'écran suivant s'affiche. Parcourir l'arborescence du disque, puis sélectionner le Fichier OVF correspondant à l'appliance vCenter Operations Manager téléchargée sur le site de VMware.
Cliquer sur Next.
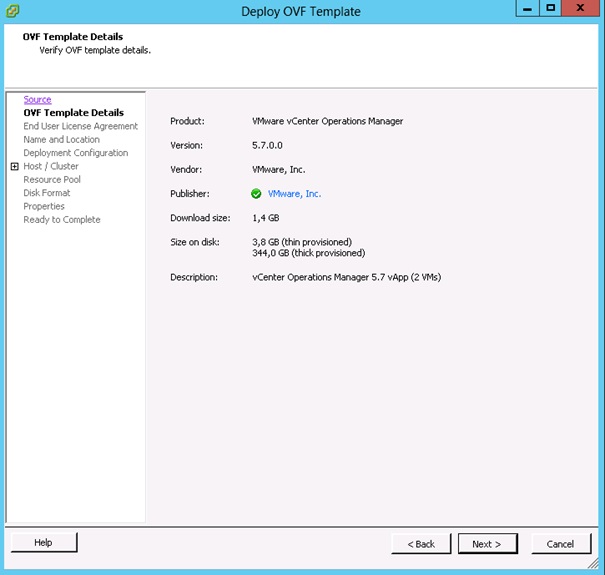
Cliquer sur Next.
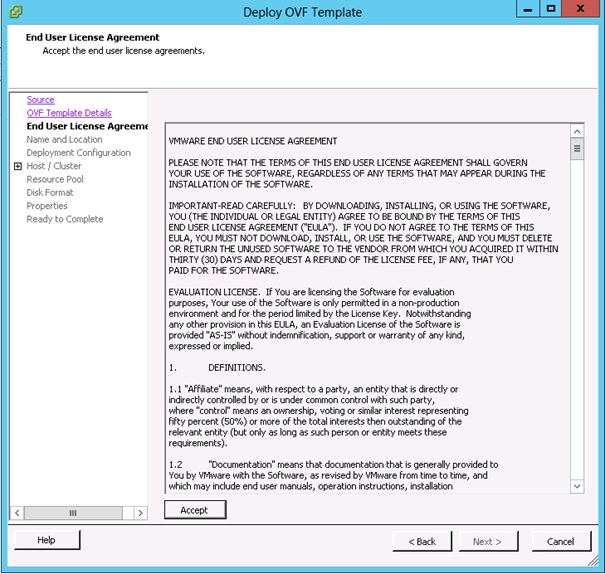
Cliquer sur Accept pour accepter les termes du contrat utilisateur final. Puis cliquer sur Next.
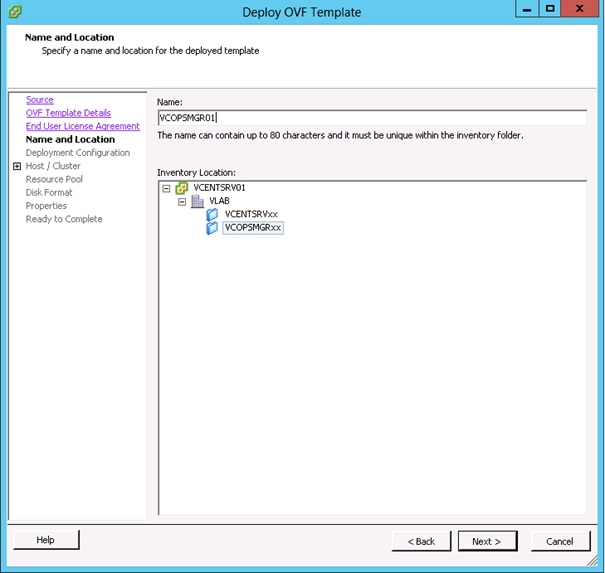
Choisir le nom et l'emplacement de la vApp dans l'inventaire du vCenter. Cliquer ensuite sur Next.
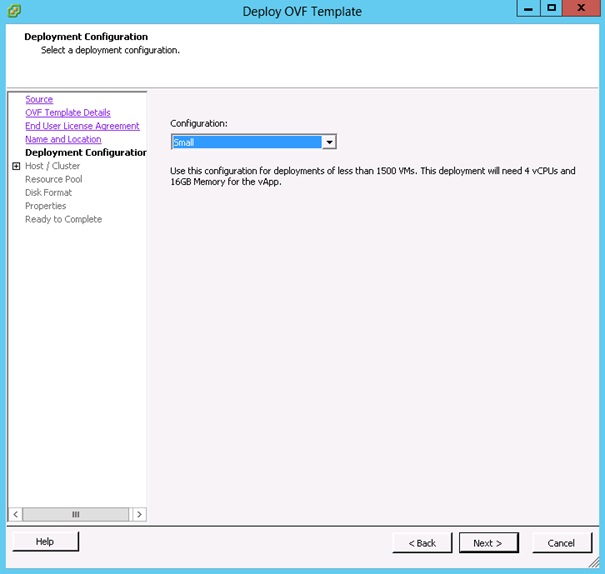
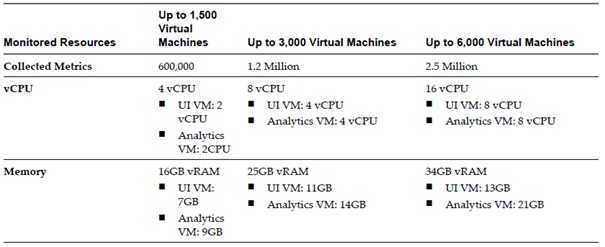
Choisir, parmi la liste des templates, la taille de l'infrastructure. Les ressources allouées à la vApp seront configurées automatiquement en conséquence. Voici les types disponibles :
- Small (<= 1500 VM) : 4 vCpu et 16 GB Ram.
- Medium (entre 1500 et 3000 VM) : 8 vCpu et 25 GB Ram.
- Large (> 3000 VM) : 16 vCpu et 34 GB Ram.
Puis cliquer sur Next.
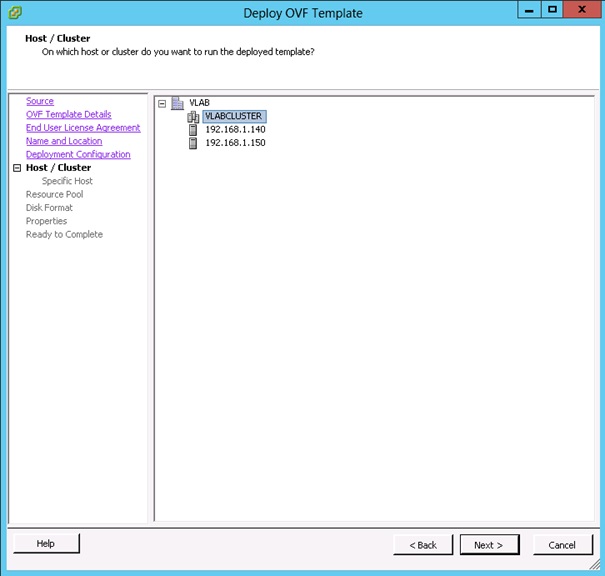
Choisir l'emplacement (hôte/cluster) qui hébergera la vApp VMware Operations Manager puis cliquer sur Next.

Choisir le datastore sur lequel seront stockés les fichiers composant la vApp vCenter Operations Manager,puis cliquer sur Next.
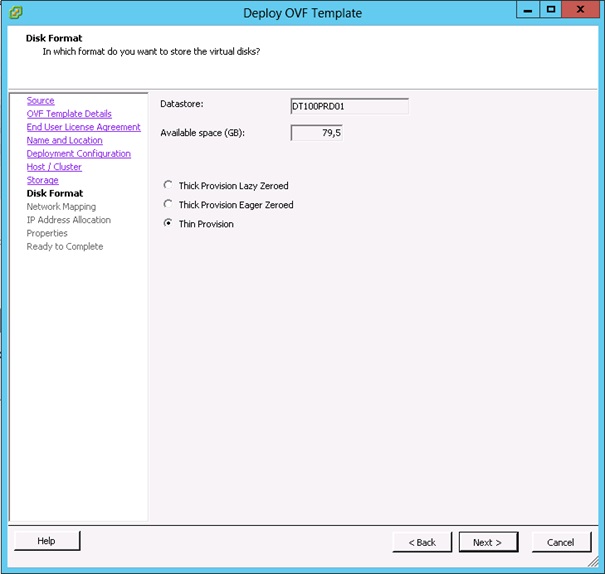
Choisir le type d'allocation des fichiers de disques de la vApp (Lazy Thick, Eager Thick ou Thin), puis cliquer sur Next.
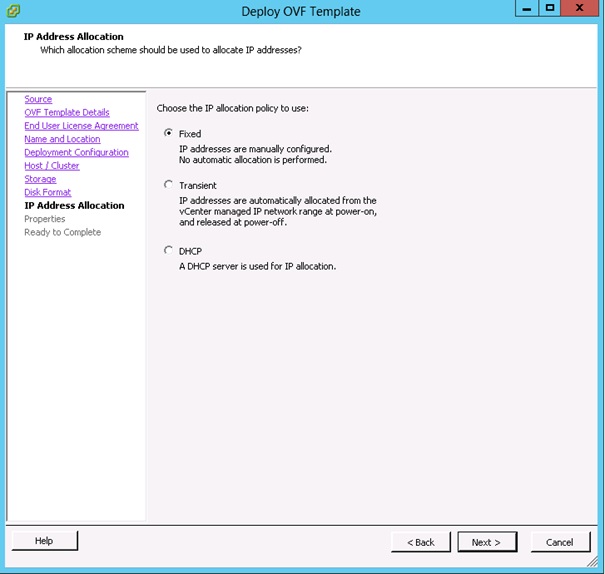
Choisir la politique d'adressage IP. Puis cliquer sur Next.

Choisir la timezone et les adresses IP des deux VM composant la vApp vCenter Operations Manager, puis cliquer sur Next.
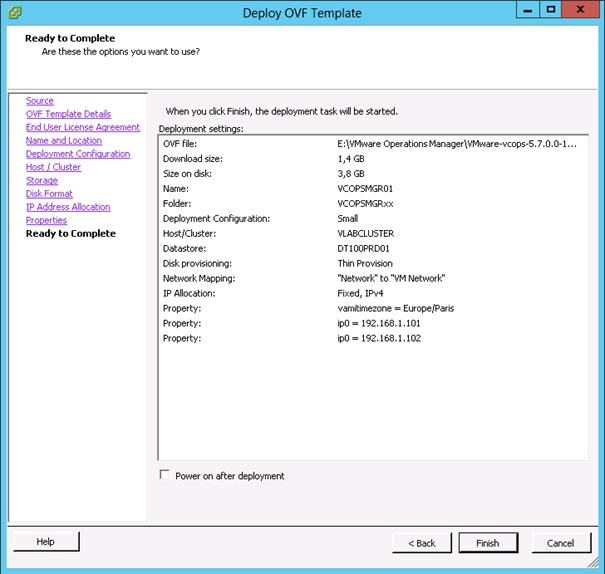
Cliquer sur Finish.
La progression du déploiement s'affiche via une Pop-Up et également dans le panneau Recent Tasks du vSphere Client.

Le déploiement est terminé.
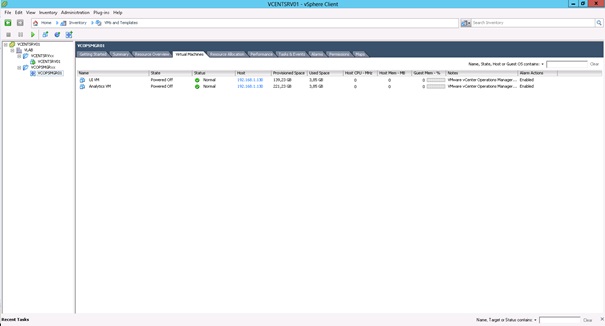
La vApp s'affiche dans la vue VM and Templates de l'inventaire vCenter.
Et les VM qui la composent dans l'onglet Virtual Machines une fois la vApp sélectionnée.
VII. Configuration▲
Voici la marche à suivre pour configurer VMware vCenter Operations Manager de manière basique (pas de plugin/pas de linked vCenter).
Ouvrir un navigateur Internet.
Entrer l'adresse suivante : https://<hostname/ip>/admin
Avec au choix le nom de machine ou l'adresse IP de la VM UI.
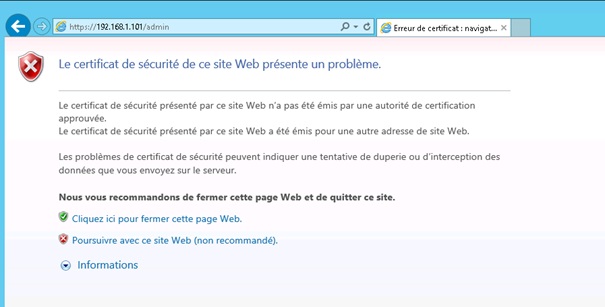
Cliquer sur Poursuivre avec ce site Web.

Se connecter en utilisant les credentials par défaut : admin/admin.
Lors de la première connexion, l'assistant de configuration démarre. La première étape consiste à renseigner les informations concernant le vCenter qui héberge l'Appliance Operations Manager.

Renseigner :
- l'adresse IP du vCenter ;
- un nom d'utilisateur autorisé à se connecter au vCenter ;
- le password de ce même utilisateur.
Vérifier également que l'adresse IP de la VM Analytics est correcte.
Puis cliquer sur Next.
Patienter durant le rafraîchissement de la configuration de vCenter Operations Manager.
Si un avertissement concernant le certificat de sécurité apparait, cliquer sur Yes pour continuer.

Changer les mots de passe par défaut des comptes admin et root de l'Appliance, dont voici les credentials par défaut : root/vmware et admin/admin. Puis cliquer sur Next.
Définir le serveur vCenter à monitorer.
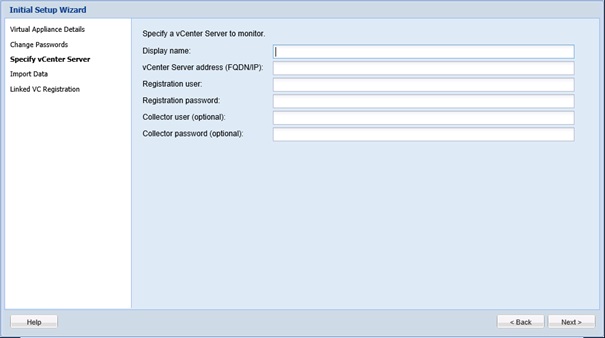
Renseigner le nom du vCenter, son FQDN/Adresse IP, un login/mot de passe
utilisateur (groupe admin) pour que l'Appliance puisse s'enregistrer avec le vCenter, et un login/mot de passe utilisateur (optionnel) pour la collecte des données. Puis cliquer sur Next.
Patienter durant la phase de validation.

Cliquer sur Next.
Cliquer sur Finish.
Patienter durant l'enregistrement de vCenter Operations Manager avec le vCenter Server.
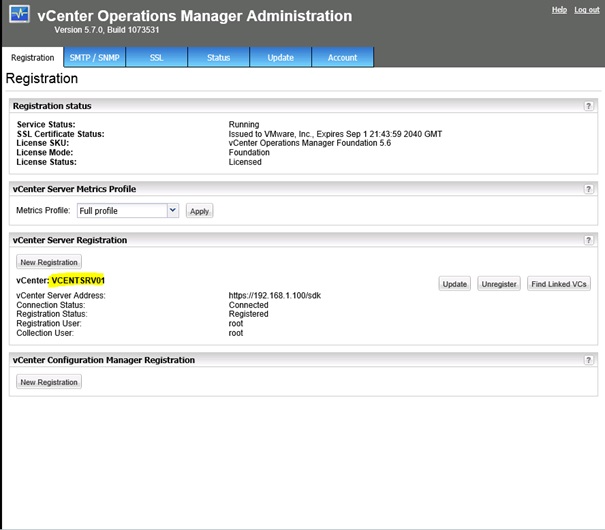
L'opération est correctement terminée et le vCenter apparait bien dans l'onglet Registration du panneau d'administration de vCenter Operations Manager.
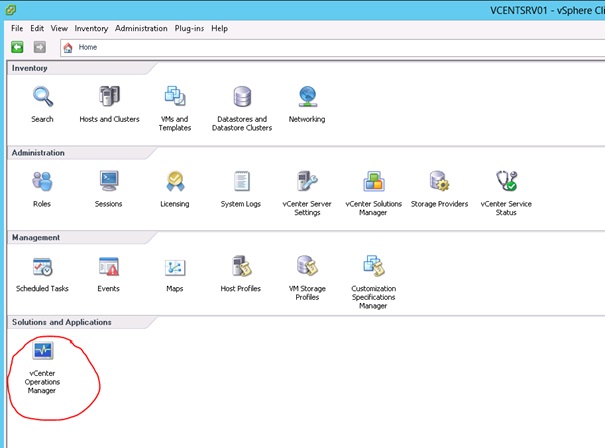
De même, dans le vSphere Client, une nouvelle icône vCenter Operations Manager est apparue.
Operations Manager est maintenant opérationnel.
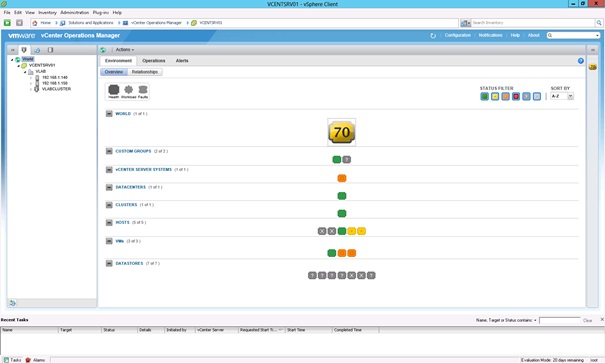
VIII. Présentation du dashboard et des badges principaux▲
Cet article a pour but de présenter le Dashboard (tableau de bord) de VMware vCenter Operations Manager. Il s'agit du premier écran affiché lors de la connexion à l'interface graphique (UI) de vCenter Operations Manager.
Pour se connecter à la UI, ouvrir un navigateur Web et entrer l'adresse suivante :
https://192.168.1.101/vcops-vsphere
Utiliser le compte admin par défaut et le mot de passe renseigné lors de la configuration initiale de vCenter Operations Manager.
Une fois connecté, le Dashboard s'affiche.
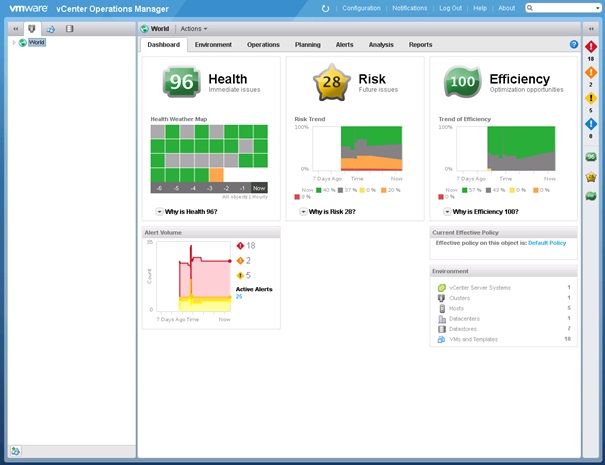
Entrons à présent dans le détail des différentes parties de ce Dashboard.
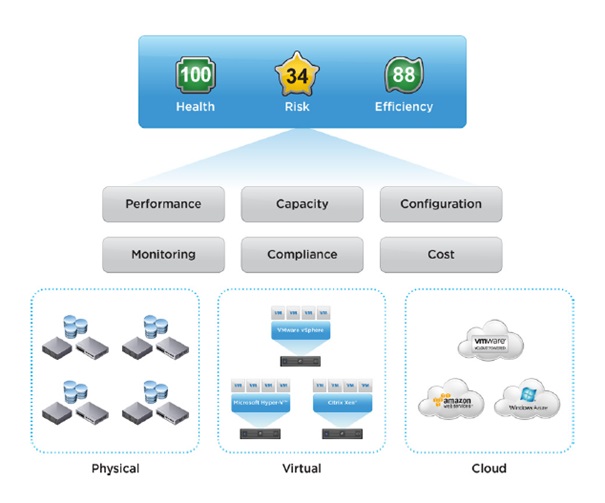
Les trois badges principaux sont les suivants :
- health ;
- risk ;
- efficiency.

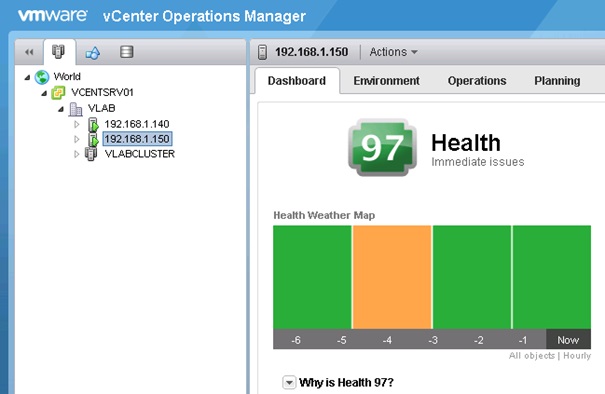
Le badge Health permet de déterminer l'état de santé de l'infrastructure virtuelle vSphere. Il permet d'identifier les objets qui nécessitent une attention immédiate pour éviter des problèmes futurs.
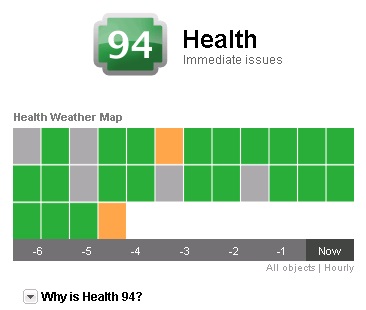
Le score général du badge est une valeur entre 0 et 100, plus la valeur est haute et mieux le système se porte. Elle est calculée selon un score par Workload, le nombre d'anomalies et de fautes. Cette vue permet d'avoir un aperçu de tous les objets en même temps, chaque objet pouvant être survolé (affichage des propriétés de l'objet) ou cliqué (affichage des détails de l'objet), elle permet en outre de suivre l'évolution du système heure par heure au cours des 6 dernières heures (-6 à Now).
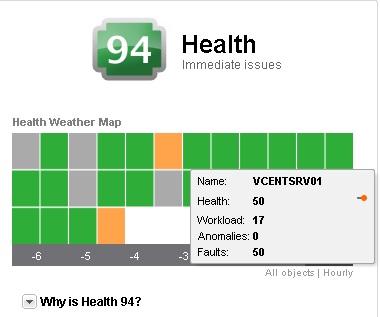
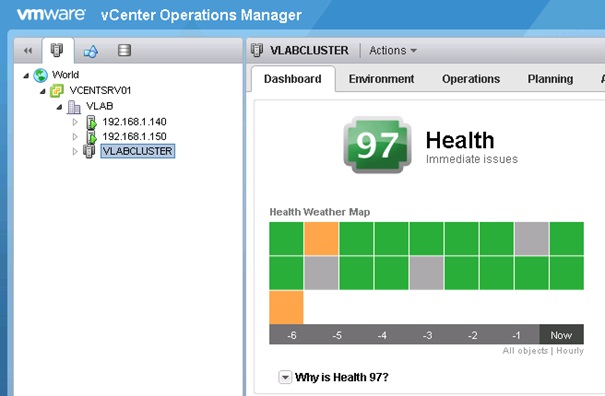
La vue est dynamique et affiche l'ensemble des objets dépendant de l'élément sélectionné dans l'inventaire de la console vCenter Operations. Le score global quant à lui reste constant. Les deux captures d'écran ci-dessous présentent la vue Health avec un cluter sélectionné puis un host standalone.
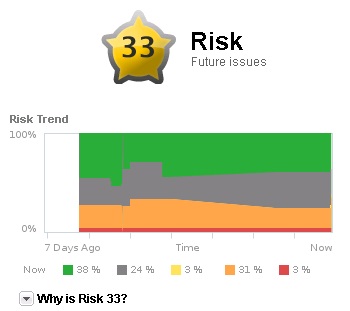
Le badge Risk présente la probabilité de se retrouver confronté à des problèmes futurs qui pourront occasionner une dégradation de la performance globale. Le score est compris entre 0 et 100, plus il est bas et plus le risque est faible. Il est agrémenté d'une courbe présentant l'évolution du risque sur les sept derniers jours (7 Days ago à Now). Le risque est calculé d'après différentes métriques (temps restant, capacité restante, respect des normes, stress).
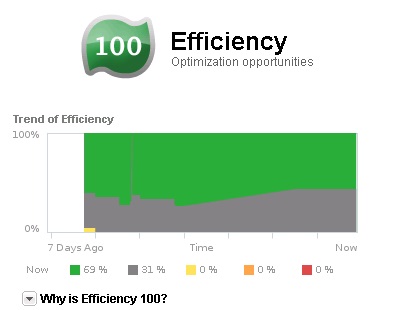
Le dernier badge est le badge efficiency. Il permet de déterminer l'efficacité délivrée par le système courant et permet d'identifier les éventuels problèmes de performances et opportunités d'optimisation pour améliorer l'efficacité globale et les performances de l'infrastructure vSphere. L'efficacité prend en compte les compteurs de gaspillage, et de densité de l'infrastructure. Le score est compris entre 0 et 100, plus il est élevé, meilleure est l'efficacité générale. Ce score permet d'économiser en améliorant l'utilisation des ressources. Trois ressources sont considérées : le CPU, la mémoire et l'espace disque. Il est agrémenté d'un graphique permettant d'afficher les différents niveaux d'efficacité des objets sur les sept derniers jours (7 Days Ago à Now).
IX. Présentation des badges secondaires▲
Nous avons vu dans l'article précédent sur Operations Manager, que le Dashboard se composait de trois badges principaux qui pour rappel sont les suivants :
- health ;
- risk ;
- efficiency.
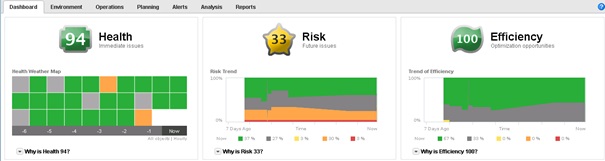
Ces trois badges indiquent un score entre 0 et 100 calculé d'après des indicateurs différents. Ces badges principaux sont plutôt destinés aux administrateurs Operations. Pour chaque badge il est possible d'afficher les différents indicateurs ayant servi au le calcul du score, il s'agit des badges secondaires qui sont eux, plutôt à destination des administrateurs Infrastructure. Pour afficher ces badges secondaires,il suffit de cliquer sur le lien Why is … ? de chaque badge principal.
Cet aperçu illustre le Dashboard avec chaque badge secondaire de chaque badge principal affiché.
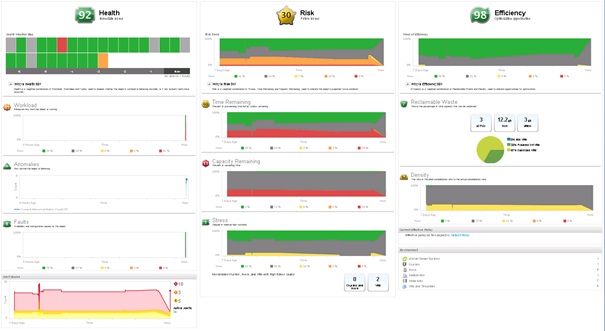
La structure est la suivante :
- Health
- Workload
- Anomalies
- Faults
- Risk
- Time Remaining
- Capacity Remaining
- Stress
- Efficiency
- Reclaimable Waste
- Density
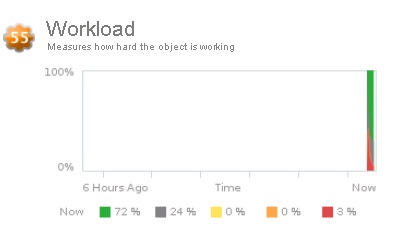
Commençons par les badges secondaires au badge Health. Le premier d'entre eux est le badge Workload. Le score de ce badge affiche le ratio entre les ressources demandées par chaque objet et sa capacité effective. Il doit-être le moins élevé possible, en effet un workload qui obtiendrait un score de 100 % signifierait que l'objet n'est plus en mesure d'obtenir des ressources suffisantes pour fonctionner de manière optimale (problèmes de performances notamment). Les paramètres pris en compte pour le calcul de ce badge sont les suivants : CPU, Mémoire, I/O Disques, I/O Réseau. Dans certains cas, il est possible que le score excède 100, ce qui signifie que l'objet essaye d'obtenir plus de ressources que ce qu'il est autorisé (overcommit). Le Dashboard présente le badge Workload de l'infrastructure complète et son évolution au cours des 6 dernières heures, le détail pour chaque objet peut également être affiché.
Le badge secondaire suivant est le badge Anomalies. Ce badge affiche les Anomalies rencontrées par les objets selon des métriques relevées pour chaque objet. Les seuils de chaque métrique sont calculés par Operations Manager et les anomalies générées si l'objet a atteint l'un de ces seuils. Le score global correspond à la somme des anomalies calculées sur l'infrastructure. Plus bas est le nombre d'anomalies relevé, mieux se porte l'infrastructure.

Le dernier badge secondaire du badge Health est le badge Faults. Ce badge affiche la liste des problèmes rencontrés par un objet, ces problèmes sont extraits des Events du vCenter. Le score global correspond à la somme des Faults des objets subséquents. Il inclut des évènements tels que : la perte d'une redondance de NIC, de HBQ, des erreurs mémoires, des pertes de connexion… Les Faults requièrent une attention immédiate de la part de l'administrateur vSphere, chaque Fault à son propre « poids » et le score global est calculé en additionnant ces poids. Plus un évènement est important/grave/critique, plus son poids est élevé.
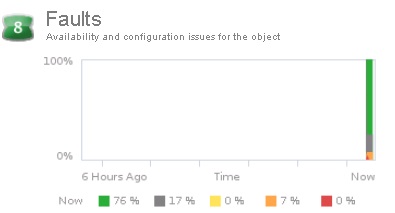
Le dernier badge secondaire du badge Health est le badge Faults. Ce badge affiche la liste des problèmes rencontrés par un objet, ces problèmes sont extraits des Events du vCenter. Le score global correspond à la somme des Faults des objets subséquents. Il inclut des évènements tels que : la perte d'une redondance de NIC, de HBQ, des erreurs mémoire, des pertes de connexion… Les Faults requièrent une attention immédiate de la part de l'administrateur vSphere, chaque Fault à son propre « poids » et le score global est calculé en additionnant ces poids. Plus un évènement est important/grave/critique, plus son poids est élevé.
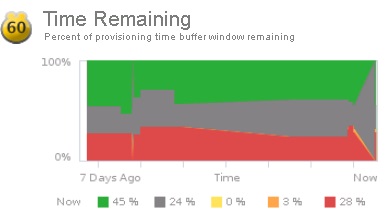

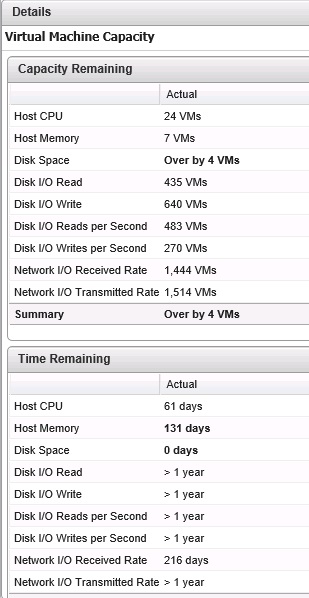
Le second badge secondaire au badge Risk est le badge Capacity Remaining. Ce badge permet de mesurer la capacité de l'infrastructure à recevoir de nouvelles VM. Un compteur représente la capacité de l'objet à recevoir de nouvelles VM et un nombre estimé de VM pouvant être créées sur l'objet est indiqué, basé sur un slot moyen de VM calculé. Chaque objet a sa propre taille de slot (datastore, host, cluster…). Une capacité de 0 signifie que l'objet n'est plus en mesure d'héberger de nouvelles machines virtuelles, auquel cas le nombre de VM responsables de cet overprovisioning sera affiché.

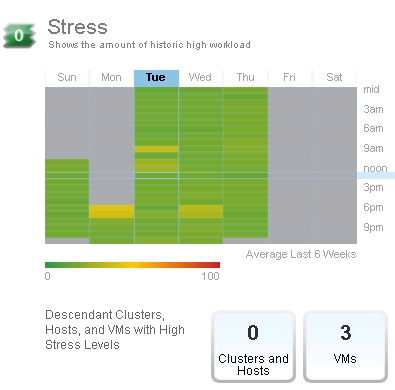
Le dernier badge secondaire au badge Risk est le badge Stress. Ce badge affiche le degré de stress de l'objet sélectionné sous forme d'agenda et est calculé sur une longue période. Le score est calculé en fonction du ratio entre la demande en ressources et la capacité effective (comme le badge Workload) mais sur une plus longue période. Ce badge permet d'identifier les hosts/VM/clusters qui n'ont pas assez de ressources allouées pour fonctionner de manière optimale sur une longue période. Il peut indiquer que trop de VM sont exécutées sur un objet. Son score est compris entre 0 (bon) et 100 (mauvais).
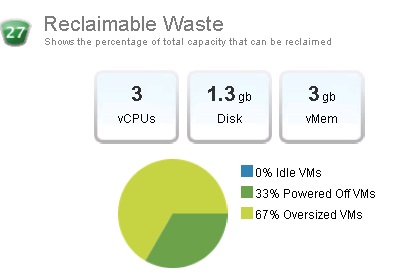
Passons maintenant aux badges secondaires au badge Efficiency, le premier d'entre eux étant le badge Reclaimable Waste. Ce badge représente l'overprovisionnement de l'infrastructure ou d'un objet. Il est calculé pour chaque ressource (CPU, mémoire, stockage) et pour chaque objet. Il permet d'identifier la quantité de ressources qui peuvent être réclamées et provisionnées par d'autres objets de l'environnement. Le score est compris entre 0 (bon) et 100 (mauvais) et la couleur change selon les niveaux de contention définis par l'administrateur vCenter Operations Manager.
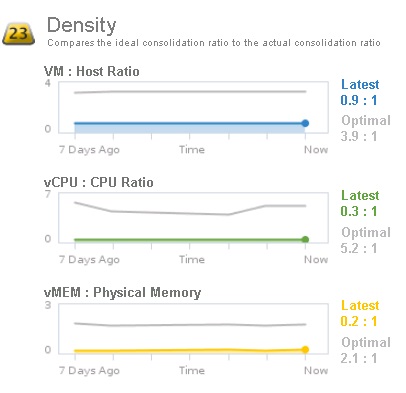
Le deuxième et dernier badge secondaire au badge Efficiency est le badge Density. Ce badge montre la densité d'objets au sein de l'infrastructure ou de l'élément sélectionné. Il s'agit d'une représentation du ratio de consolidation, comparant le ratio actuel au ratio idéal calculé en fonction de la demande, de la capacité virtuelle et de la capacité physique de l'infrastructure. Ce badge permet d'établir la quantité de ressources qui peuvent encore être provisionnées avant que ne surviennent les contentions ou conflits entre les objets. Les ratios sont les suivants : VM par hôte, nombre de vCPU par CPU physique, quantité de mémoire virtuelle par rapport à la quantité de mémoire physique. Pour chaque ratio, la valeur courante et la valeur optimale sont affichées.
X. Groupes d'opérations intelligents▲
Les groupes d'opérations intelligents sous vCenter Operations Manager permettent d'avoir un aperçu opérationnel de l'état de santé de l'infrastructure, des risques et de l'efficacité des ressources par application, secteur d'activité, workload, ou d'autres types d'entités. L'appartenance à un groupe est mise à jour de manière dynamique pour refléter les changements de l'infrastructure et afficher des informations en temps réel.
Sur chaque groupe peuvent être liées des règles définissant l'appartenance ou non au groupe, et des politiques comme les seuils des différents badges ou encore la gestion des alertes.
Voici maintenant un exemple de création de groupe. Pour créer le groupe, ouvrir la console de gestion de vCenter Operations.
Cliquer sur le bouton Actions puis sur Create new group.
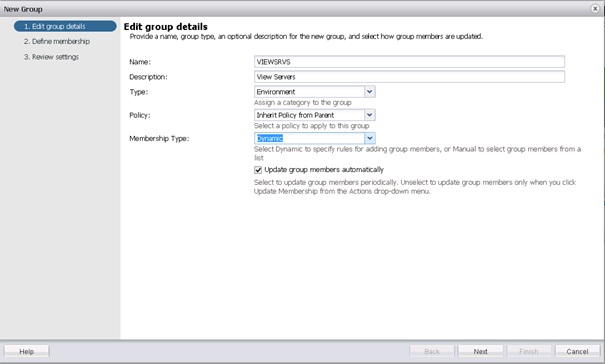
La première étape consiste à donner un nom au groupe. Puis une éventuelle description. Il faut également choisir un type de groupe, qui permet de lui assigner une certaine catégorie parmi les catégories suivantes :
- Environment : groupe basé sur un certain environnement ;
- Function : groupe basé sur une certaine fonction ;
- Service Level Objective : groupe basé sur un certain niveau de service ;
- Location : groupe basé sur la localisation ;
- Department : groupe basé sur un certain département/service ;
- Security Zone : groupe basé sur une zone de sécurité.
Définir également la policy à appliquer au groupe (héritée, par défaut…).
Puis enfin le type d'appartenance (statique/dynamique).
Cliquer ensuite sur Next.
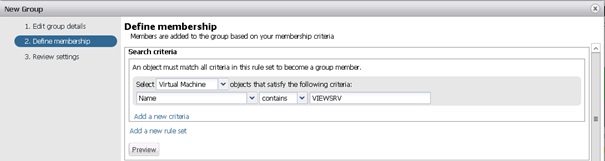
La prochaine étape permet de définir les membres du groupe. Pour un groupe dynamique, le processus permet de définir une requête multicritère sur différents types d'objets :
- All (tout type d'objet) ;
- Virtual Machine (machine virtuelle) ;
- Host (hôte) ;
- Cluster (cluster) ;
- Datastore (datastore) ;
- vCenter Server (serveur vCenter) ;
- Datacenter (datacenter),
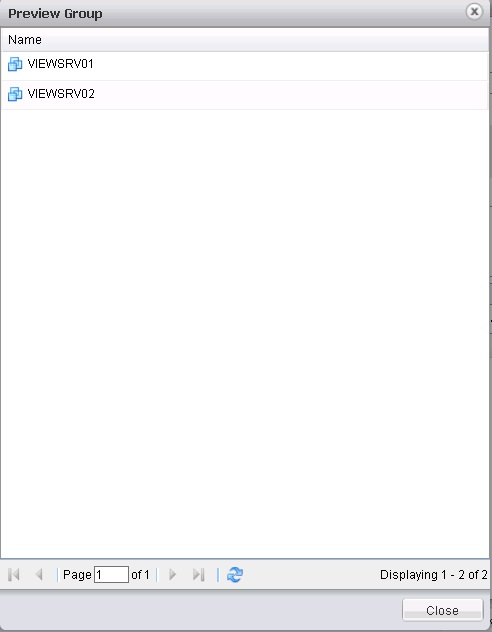
Une fois la requête définie, le bouton Preview permet d'avoir un aperçu du résultat retourné par la requête.
Il est également possible d'ajouter des serveurs « Always included » (toujours inclus) et « Always Excluded » toujours exclu qui feront toujours ou inversement jamais partie du groupe, même s'ils répondent ou ne répondent pas aux critères de la requête de sélection.
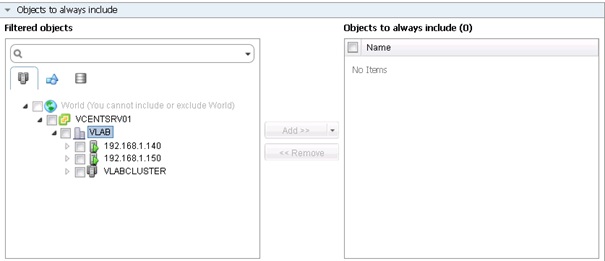
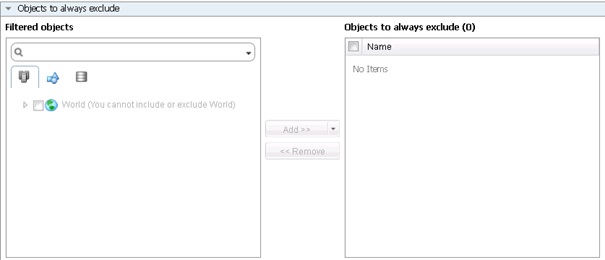
Une fois la requête définie, cliquer sur Next.
Vérifier les paramètres du groupe et cliquer sur Finish pour le créer.
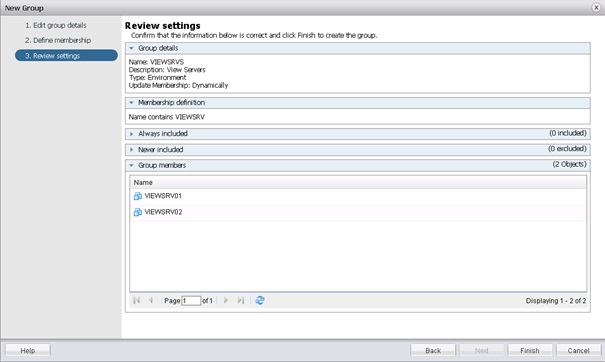
Pour afficher la liste des groupes, il faut cliquer sur le deuxième onglet au-dessus de l'inventaire dans le panneau de gauche de la console.

En sélectionnant le groupe, il est possible de l'éditer, le cloner, le supprimer, mettre à jour ses membres ou de gérer la policy du groupe.
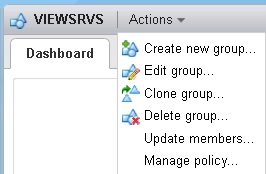
À noter également que des groupes sont par défaut créés pour chaque folder de la vue VM and Templates de l'inventaire du vCenter Server.
XI. Policies▲
Les Policies sous vCenter Operations Manager s'appliquent sur les groupes d'objets pour personnaliser par exemple les seuils des différents badges, la gestion de la capacité ou encore des alertes. Elles peuvent être appliquées sur un ou plusieurs groupes.
L'assignation d'une Policy à un groupe n'est pas obligatoire (présence d'une policy par défaut), les objets peuvent appartenir à un ou plusieurs groupes avec des policies différentes. Si des policies viennent à entrer en conflit, la policy par défaut est toujours celle qui a la priorité moindre.
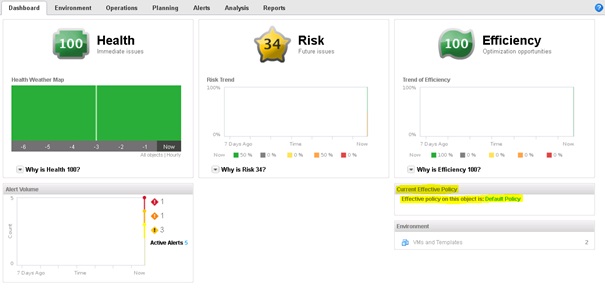
L'affichage des policies appliquées sur les objets se fait sur le Dashboard.
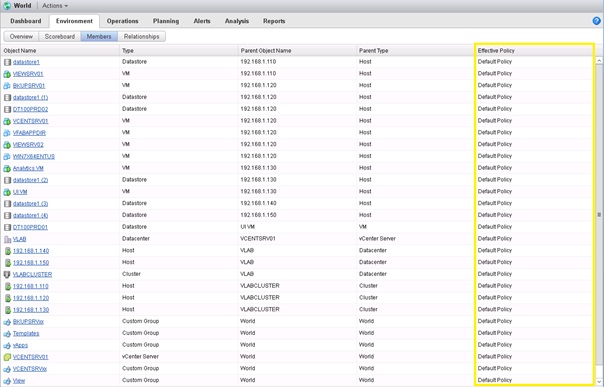
Ou dans l'onglet Environment, sous-onglet Members pour chaque membre.
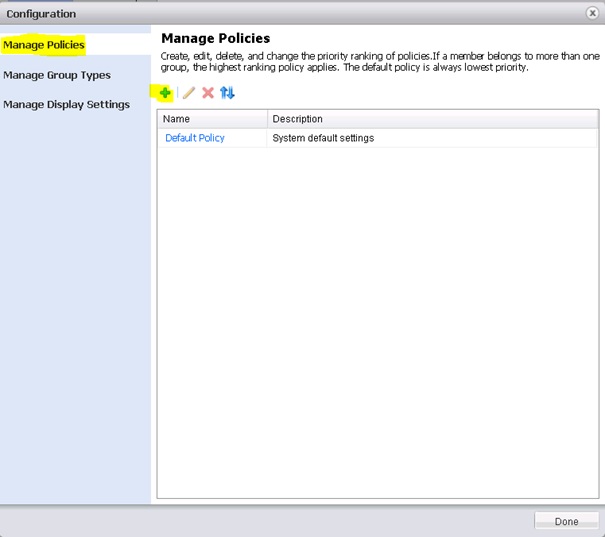
Pour créer une Policy, voici la marche à suivre.
Cliquer sur le lien Configuration en haut à droite de la console de gestion.

Dans la partie Manage Policies, cliquer sur le bouton + vert.
Renseigner le nom de la Policy (éventuellement une description). Il est également possible de cloner depuis une Policy existante, dans ce cas, les différents champs de configuration de la Policy seront préremplis en utilisant les valeurs de la Policy choisie dans la liste déroulante Clone From.
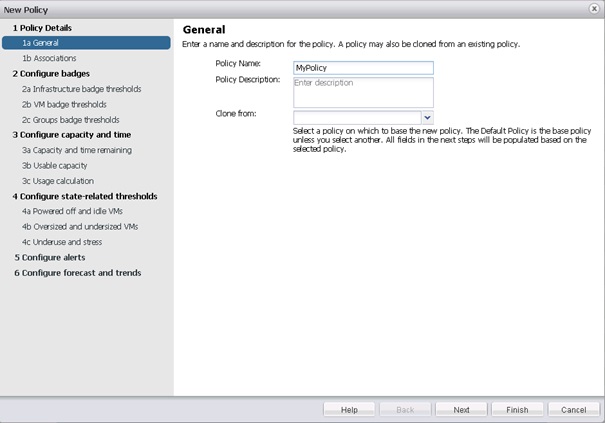
Cliquer sur Next.
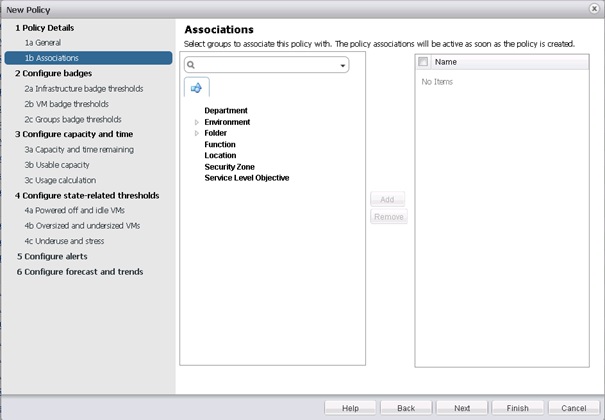
Il est possible de choisir les différents groupes auxquels sera assignée la Policy en cours de création. Il est également possible de ne pas choisir de groupe à cette étape, puis d'assigner manuellement la policy ultérieurement. Cliquer sur Next.
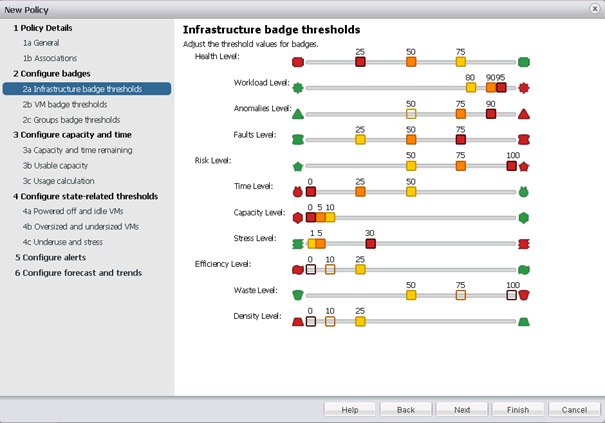
Nous entrons maintenant dans la partie qui permet de définir les seuils de chacun des badges de la partie infrastructure. Pour chacun des badges principaux, les différents badges secondaires sont affichés. Cet écran permet de définir à partir de quel score la couleur du badge change pour les éléments de l'infrastructure. Définir les différents seuils puis cliquer sur Next.
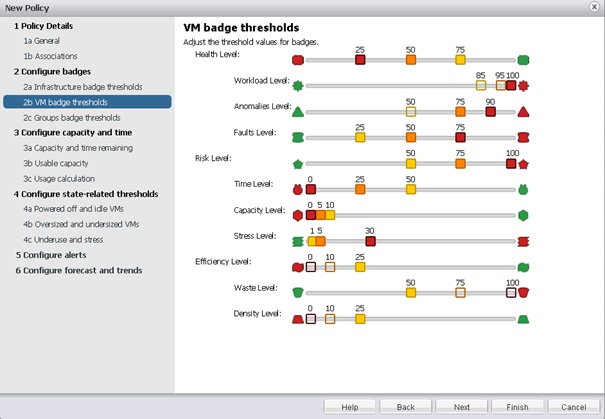
La partie suivante consiste à définir les seuils des badges, mais au niveau des machines virtuelles cette fois-ci.
Enfin, le dernier écran permet de définir ces seuils pour le groupe en entier.

Il est possible de désactiver un seuil en double-cliquant sur celui-ci. Un carré « vide » correspond à un seuil désactivé et un carré « plein » à un seuil activé.
Les prochains seuils à définir sont ceux de capacité et temps restants.
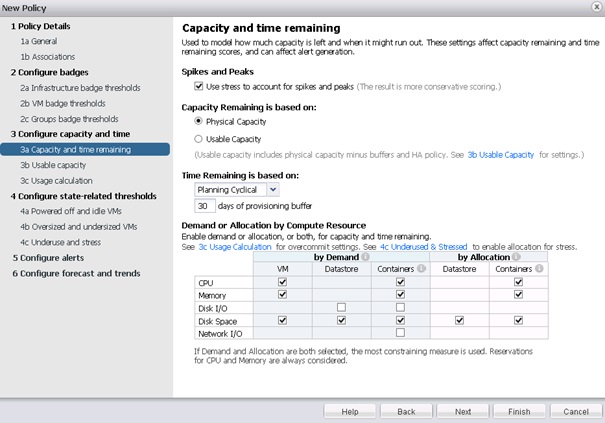
La capacité utilisée pour le badge Remaining Capacity peut être la capacité physique ou la capacité utilisable (capacité physique moins les buffers et les ressources allouées au HA). La base du score du badge Time Remaining peut également être modifiée (par défaut, le score est basé sur un buffer de 30 jours de capacité restants). Le tableau Demand or Allocation by Compute Ressource permet de modifier les ressources utilisées pour le calcul des badges Capacity Remaining et Time Remaining, selon la demande et/ou l'allocation effective des ressources sélectionnées.
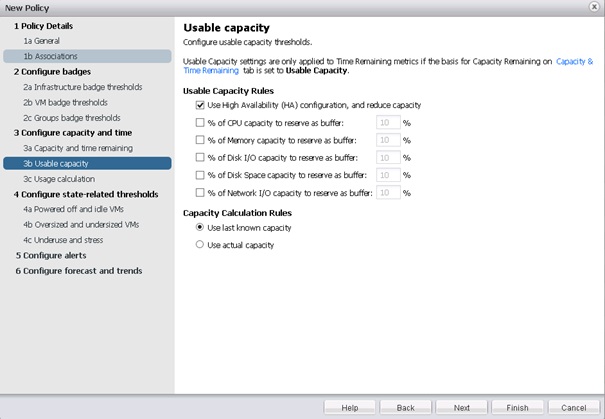
L'écran suivant permet de définir quels sont les paramètres à prendre en compte dans le calcul de la capacité utilisable. Par défaut, seuls les paramètres HA sont pris en compte, mais il est possible également de définir des buffers CPU, mémoire, I/O Disques et réseaux ou d'espace disque.
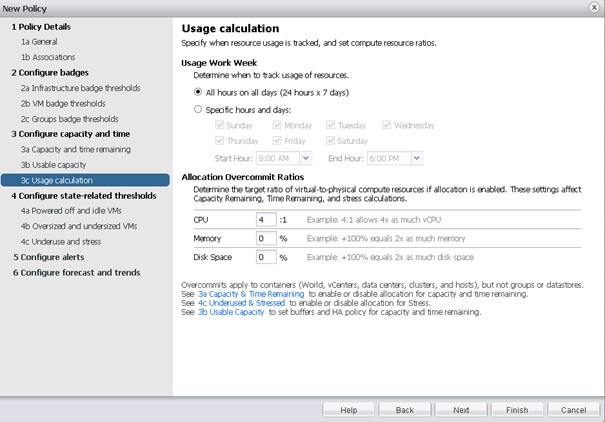
Il est également possible de définir les règles de calcul de l'utilisation des ressources. Par exemple en limitant le calcul de l'utilisation des ressources à certains jours et heures (par défaut le calcul est fait sur une base 7j/7 24h/24), ou encore de modifier les ratios d'overcommit en termes de ressources CPU, mémoire ou d'espace disque.

Les seuils peuvent également être définis en fonction de l'état des VM et des VM qui tournent en Idle.
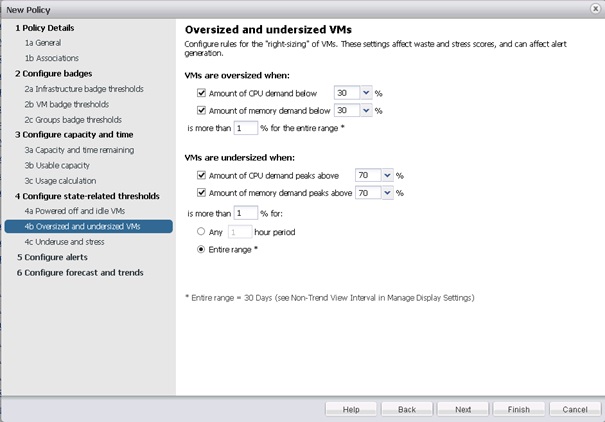
Ou encore pour définir les VM étant surdimensionnées ou sous-dimensionnées (en termes d'utilisation CPU ou Mémoire).
Enfin, il est possible de définir le niveau à partir duquel :
- un objet sera sous-utilisé ;
- le stockage sera considéré comme gaspillé (snapshots et templates) ;
- un objet sera considéré comme stressé.
Enfin, les changements de couleur des badges peuvent générer des alertes, il est possible de définir sur quels objets ces alertes seront ou non générées.
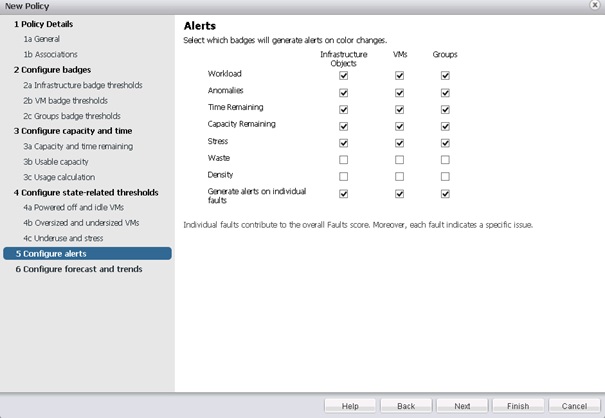
Le dernier écran permet de paramétrer les prévisions et tendances.

XII. Présentation de l'onglet Environment▲
L'onglet Environment de vCenter Opertaions Manager permet d'afficher les informations concernant les différents badges de manière synthétique et structurée via des sous-onglets. Cette vue permet de rapidement identifier les problèmes sur des objets ou les relations interobjets. Voici un exemple d'affichage de l'onglet Environment.
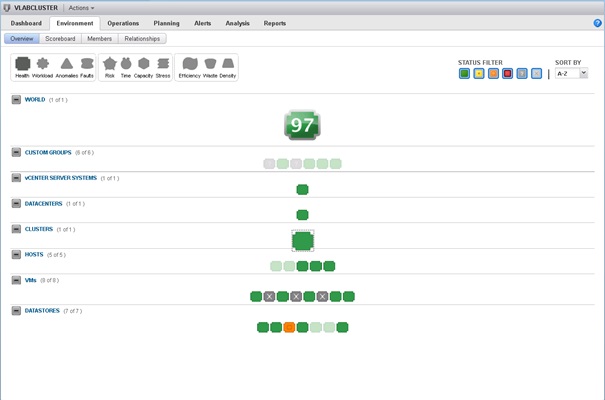
L'élément sélectionné ici est de type Cluster. On constate que les éléments liés à ce cluster sont ici mis en surbrillance.
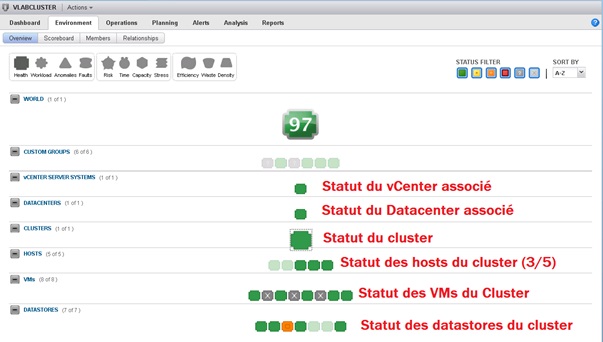
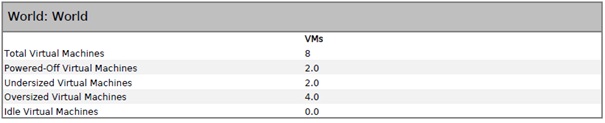
Dans cet exemple, on constate que notre cluster n'est membre d'aucun des groupes définis. On constate également que le badge Health du vCenter associé à ce Cluster est au vert. Le statut du datacenter et de notre cluster est également au vert. Sur cinq hosts dans l'infrastructure, trois sont membres du cluster et sont également verts. Enfin, sur les huit VM de notre cluster, cinq sont au vert et trois ne remontent pas d'informations (VM éteintes/templates). Sur les sept datastores de notre infrastructure, cinq font partie/sont exposés au cluster (trois correspondent au datastore local des hosts et deux aux datastores partagés) et deux ne font pas partie du cluster (datastores locaux des deux hosts non mis dans le cluster). Enfin, sur ces datastores, un d'entre eux a son badge de couleur orange.
Il est possible de naviguer entre les différents badges via le bandeau en haut de la page.

Un autre bandeau permet de filtrer selon les seuils que l'on souhaite afficher pour le badge sur chaque objet.

Exemple ci-dessous sur notre cluster.

Seuls les badges dont la couleur n'est pas verte ont été affichés, nous y retrouvons notre datastore.
L'onglet Scorebaord permet d'afficher de manière graphique la corrélation entre les badges secondaires pour les badges principaux. Une liste déroulante permet de sélectionner le badge principal à afficher et le graphique montrant la corrélation entre les badges secondaires est automatiquement affiché. Le tableau inférieur présente l'évolution du score des badges secondaires des objets enfants à l'objet sélectionné sur les 7 derniers jours.
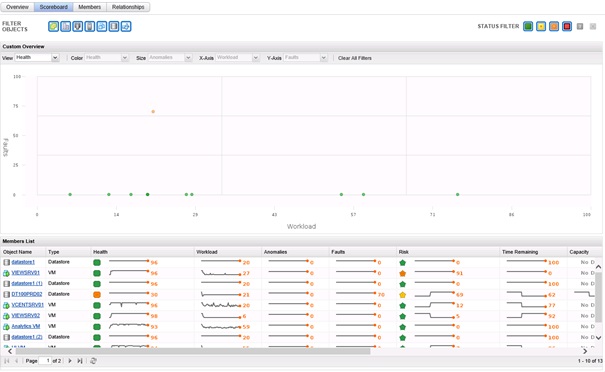
L'onglet Members affiche la liste des objets enfants à l'objet sélectionné, il permet entre autres d'afficher la Policy appliquée sur l'objet, mais aussi le type d'objet, son objet parent et le type de l'objet parent.
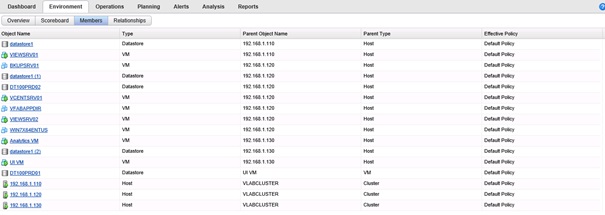
Enfin, l'onglet Relationships affiche de manière graphique la/les relations entre les différents objets enfants à l'objet sélectionné et son objet parent et leur état de santé respectif.
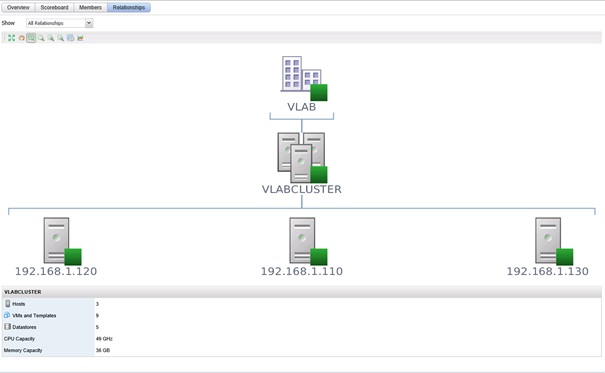
XIII. Présentation de l'onglet Operations▲
L'onglet Operations sous vCenter Operations permet d'avoir accès aux informations détaillées des différents objets de l'infrastructure vSphere. La capture ci-dessous illustre un exemple d'affichage de l'onglet Operations en ayant sélectionné un objet de type Cluster.
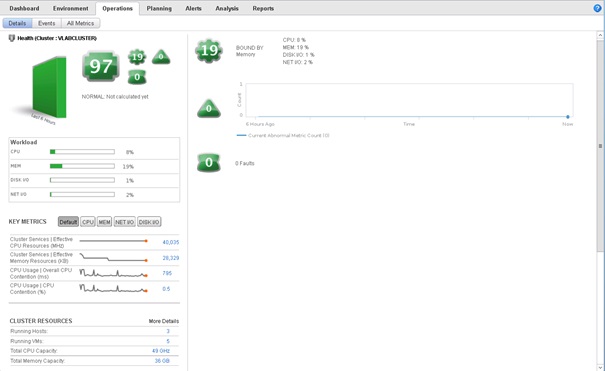
Nous voyons ici différentes parties. La première est la partie Health.

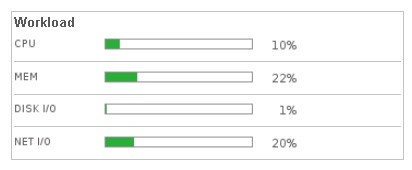
Cette partie affiche le score du badge principal Health et des différents badges secondaires associés (Workload, Anomalies, Faults). Une progressbar est ensuite affichée pour donner le détail du badge Workload (utilisation de la ressource en %) selon les différentes ressources (CPU, mémoire, i/o disques et i/o réseau).
La partie inférieure de ce panneau affiche les différentes métriques et leur évolution ainsi que le détail des ressources de l'objet sélectionné.
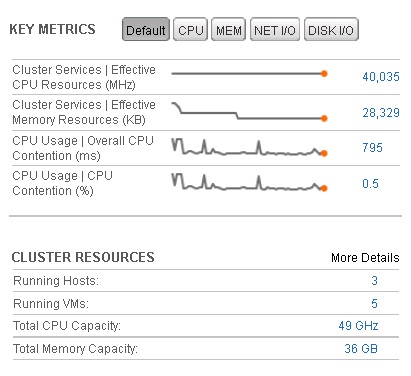
Le panneau de droite quant à lui illustre les badges secondaires, en premier lieu le badge Workload, puis l'évolution du nombre d'anomalies de l'objet sur les 6 dernières heures, et enfin le nombre de fautes.
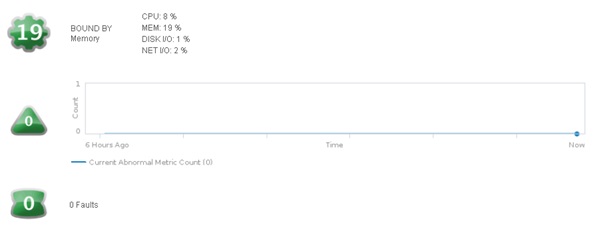
À noter que chaque badge est cliquable pour en afficher le détail. La capture ci-dessous illustre le détail du badge Workload de notre cluster.


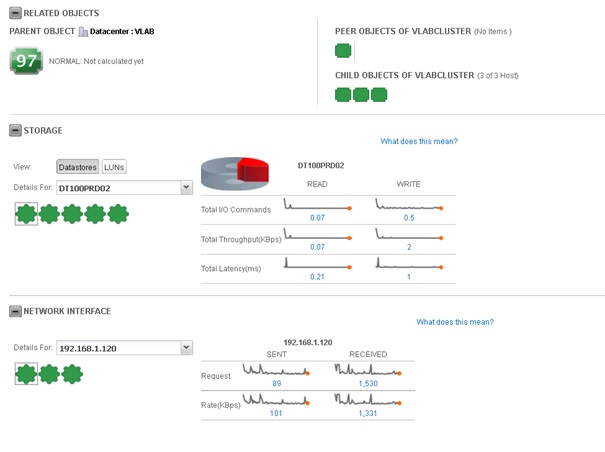
Le panneau inférieur de l'onglet Operations affiche les objets liés à l'objet sélectionné (exemple : statut des hosts et du vCenter server associés au cluster, affichage du statut du stockage associé et des interfaces réseau). Les détails affichés varient selon le type d'objet et de badge sélectionnés. Exemple pour un cluster :
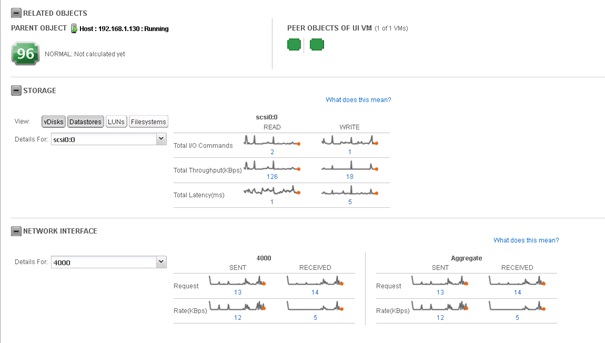
Pour une VM :
La partie Events de l'onglet Operations permet d'afficher sous forme graphique l'évolution des badges secondaires au badge Health et donc du badge Health lui-même au fil du temps. L'évolution du score est présentée sous forme d'une ligne et chaque Event sous forme d'une case.
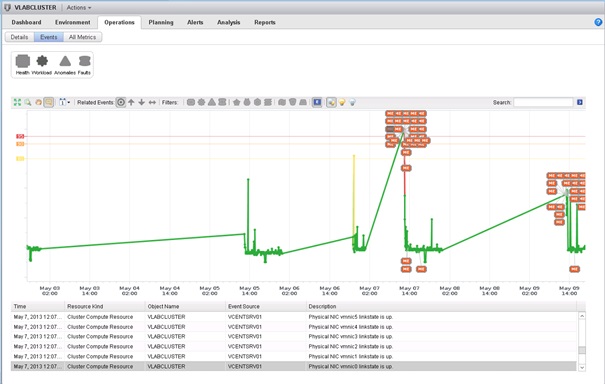
Un bandeau en haut de page permet de changer la représentation selon les différents badges.

L'affichage du résultat peut être affiné via différents filtres.

Ces filtres permettent notamment :
- de zoomer/dézoomer sur une partie du graph ;
- de filtrer sur une période donnée ;
- d'afficher les évènements liés :
- à l'objet parent,
- aux objets enfants,
- à l'objet lui-même ;
- de filtrer les évènements par type de badge secondaire/principal.
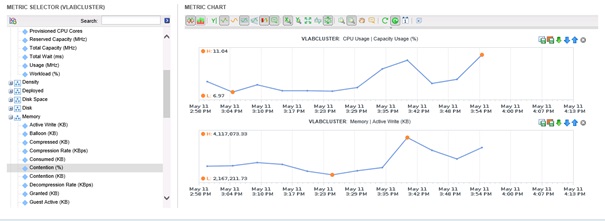
La dernière partie du panneau Opérations est la partie All Mectrics qui permet d'afficher de manière graphique toutes les métriques collectées par vCenter Operations Manager.
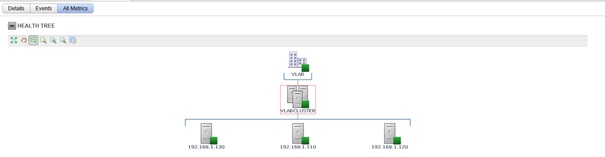
La partie supérieure de cet écran, le Health tree, permet de naviguer entre les différents objets, de connaitre leur état de santé et d'afficher les relations entre les objets (ici un cluster 3 hosts).
La partie inférieure permet de naviguer parmi les différentes métriques et de jouer avec le graphique affiché. Le résultat peut être affiché sous différentes courbes ou sur un stacked graph.
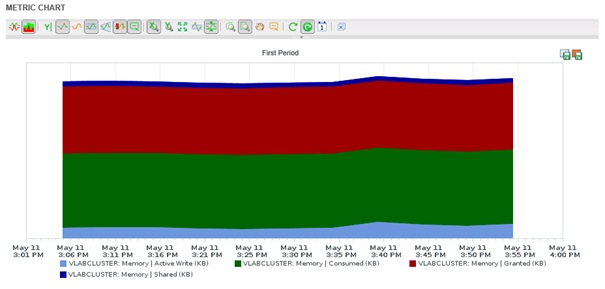
XIV. Présentation de l'onglet Planning▲
L'onglet Planning de vCenter Operations Manager permet de monitorer l'utilisation des ressources de l'infrastructure vSphere, il permet entre autres de déterminer la capacité utilisée et utilisable, les éventuels plans d'upgrade de la capacité ou encore les optimisations possibles.
Le premier sous-onglet est l'onglet Summary qui résume les informations principales telles que :
- l'estimation du temps restant avant utilisation complète des ressources ;
- nombre de VM pouvant encore être déployées avant utilisation des ressources ;
- les ressources qui posent le plus de problèmes.

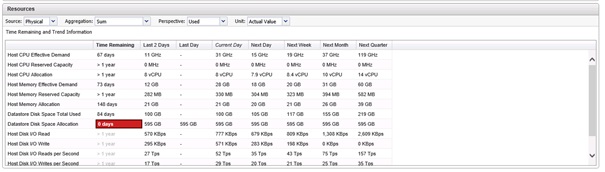
Le graphique Trends and Forecast en haut à gauche permet d'afficher le nombre d'objets restants pouvant-être ajoutés (cluster/Hosts/VM) selon l'objet sélectionné. Le tableau Extended forecast de droite affiche les prévisions pour le jour en cours (Current Day) le jour suivant (Next Day), la semaine suivante (Next Week), le mois suivant (Next Month) et le trimestre suivant (Next Quarter). Un tableau Time remaning permet d'afficher une prévision avant utilisation complète des ressources en nombre de jours.
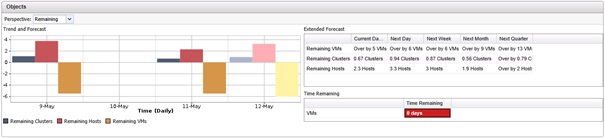
Le tableau Objects affiche le détail pour chaque ressource en termes de temps restant, et ce pour les deux dernières semaines, la semaine dernière, la semaine courante, la semaine prochaine, le mois prochain et le trimestre prochain. Si une ressource venait à manquer, son temps restant afficherait une case rouge 0 days comme sur l'exemple ci-dessous.
À noter qu'il est possible de générer des scénarios what-if permettant de connaitre l'impact d'un ajout de ressources ou de suppressions de VM par exemple
Le résultat des différents scénarios sera affiché dans le sous-onglet suivant : Views. Cette partie permet d'afficher sous forme de tableaux ou graphiques les différentes données des différents badges et sous badges : Time Remaining, Capacity, Stress, Compliance, Waste et Density. Pour chacun des badges, des vues sont prédéfinies de type tendance (trend) ou résumée (summary).

La sélection d'une des vues affiche dans la partie inférieure de l'écran les données propres à la vue.
Comme indiqué précédemment il est possible de définir un ou plusieurs scénarios via le panneau What-if Scenarios.
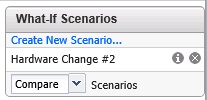
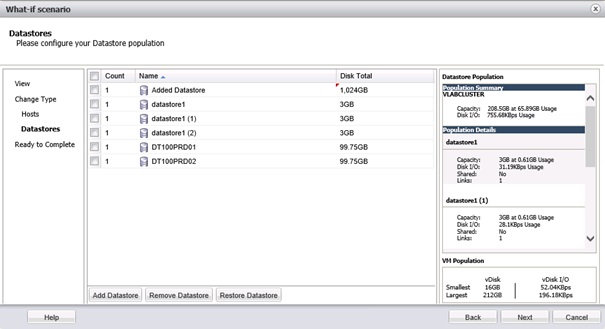
Les scénarios peuvent être de différents types selon qu'ils concernent les Hosts & Datastores ou les Virtual Machines. Différents scénarios crées peuvent être joués de manière distincte (leur résultat est donc affiché individuellement) ou combinés (le résultat à l'issue des deux scénarios est affiché).
Exemple ici avec l'ajout d'un datastore et la suppression de 5 VM.
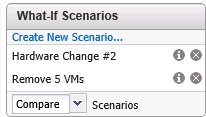
Les deux scénarios comparés.
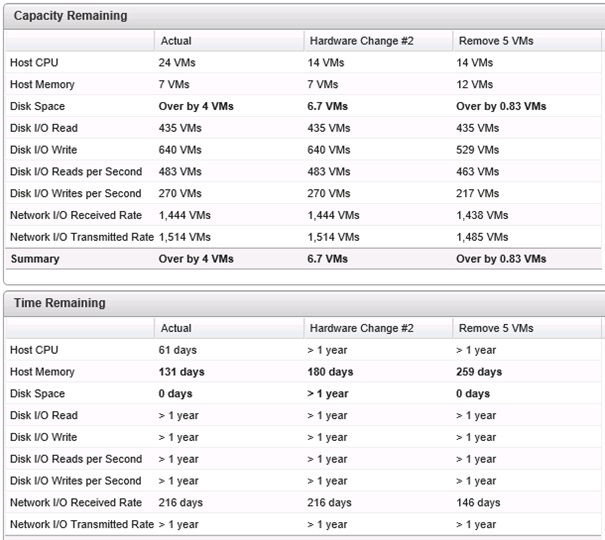
Et combinés.
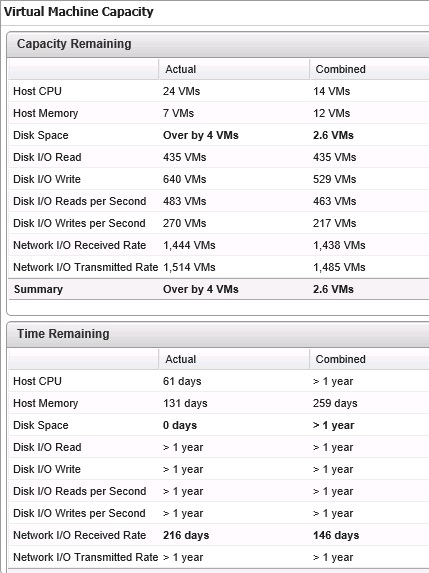
Différents types de vues sont disponibles selon le type d'informations à afficher:
- Time remaining ;
- Capacity ;
- Stress ;
- Compliance ;
- Waste ;
- Density.
Chaque vue répond à un besoin spécifique, la description de chaque vue permet de connaitre le type de besoin auquel répond la vue.

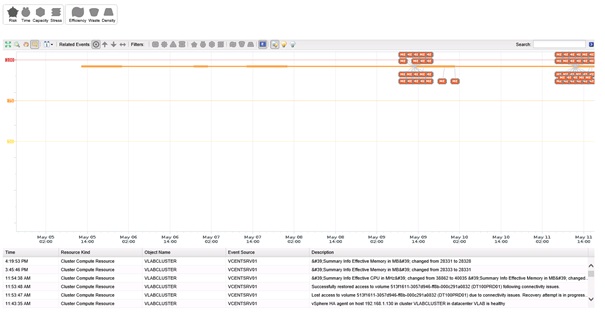
Enfin, comme dans l'onglet Operations, un sous-onglet Events est présent et permet d'afficher l'évolution du score des badges et les évènements liés à l'objet sélectionné ou ses sous-objets.
XV. Présentation de l'onglet Alerts▲
vCenter Operations offre des fonctionnalités d'alertes qui lui sont propres. Les alertes sont configurées au niveau des Policies via la boite de dialogue suivante.

Les badges sur lesquels peuvent être configurées les alertes sont les suivants :
- Workload ;
- Anomalies ;
- Time Remaining ;
- Capacity Remaining ;
- Stress ;
- Waste ;
- Density ;
- Faults.
Et la configuration peut être affinée selon le type d'objet :
- Infrastructure Objects ;
- VM ;
- Groups.
À noter que les alertes sont déclenchées pour un changement de couleur de badge, exception faite des alertes sur les Faults qui sont générées pour chaque Event.
Différents types d'alertes existent :
- les alertes liées au Score d'un badge, qui se déclenchent sur un changement de la couleur du badge selon les seuils définis pour chaque badge et type d'objet ;
- les alertes liées aux Fautes qui se déclenchent à chaque nouvel évènement ;
- les alertes administratives qui ne sont affichées que pour l'objet World et qui sont liées à des problèmes propres à Operations Manager ou à l'environnement virtuel. Elles peuvent être de deux catégories :
- les alertes système qui se déclenchent lorsqu'un composant lié au fonctionnement d'Operations Manager connait un problème,
- les alertes environnement qui se déclenchent lorsque Operations Manager cesse de recevoir les informations d'une ou plusieurs ressources et qui peuvent indiquer un problème de la ressource elle-même ou un problème de connectivité.
Des notifications peuvent également être configurées via le menu Notifications.

Les notifications requièrent une configuration SMTP pour fonctionner.

La configuration SMTP se fait via la console admin d'Operations Manager dans l'onglet SMTP/SNMP.

Les notifications se composent :
- d'un nom ;
- d'une ou plusieurs adresses mail de destinataires ;
- du type d'alertes à notifier ;
- des objets ou types d'objets concernés (objets enfants inclus ou non).
La vue Alerts permet d'afficher l'évolution du volume d'alertes sur les 7 derniers jours. Différentes couleurs permettent d'identifier la criticité des alertes. Elle est composée d'un graphique et également d'un tableau qui en affiche l'historique. Les alertes peuvent être filtrées selon le type de badge concerné, suspendues ou supprimées. Un utilisateur peut également s'assigner une alerte. Le champ texte Alert Info permet de connaitre le détail de l'alerte et ses possibles causes.
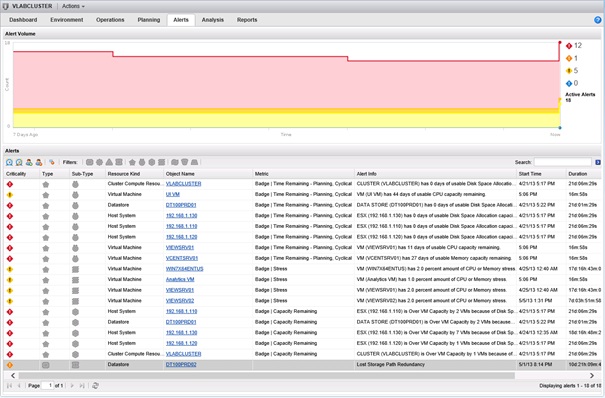
En double-cliquant sur une alerte, il est possible d'en afficher le détail qui se présente sous forme d'une pop-up.
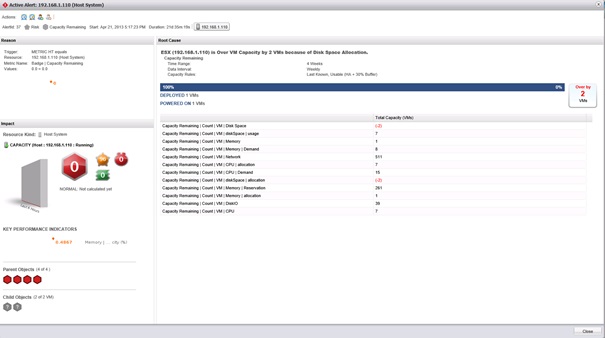
Cette pop-up affiche des informations générales sur l'alerte telles que son ID, le type de badge principal/secondaire concerné, la date de début et la durée de l'alerte ou encore l'élément concerné. Un panneau Reason identifie la raison pour laquelle l'alerte s'est déclenchée. La partie Impact permet d'identifier l'impact de l'alerte et les objets parents impactés. La partie Root cause informe sur la cause du déclenchement de l'alerte. Dans cet exemple, l'alerte concerne un datastore, la raison du déclenchement de l'alerte est la métrique « capacity remaining » qui a retourné une valeur de zéro. La cause est la sur allocation de l'espace de stockage du datastore qui est surprovisionné de 2 VM.
XVI. Présentation de l'onglet Reports▲
Outre les notifications, vCenter Operations permet de générer manuellement ou automatiquement un certain nombre de rapports. Cette fonctionnalité est accessible via l'onglet Reports.

Un certain nombre de rapports standards sont définis par défaut (11 précisément). Ces rapports standards ne sont pas modifiables et leur génération va dépendre de l'objet sélectionné dans l'inventaire (génération contextuelle).
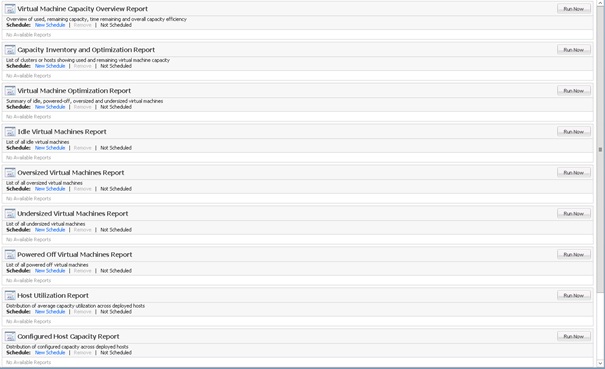
Un rapport peut être généré manuellement en cliquant sur Run Now.

Lorsque ce bouton est cliqué, la progression de la génération du rapport s'affiche sous celui-ci.

Une fois le rapport généré, le Status affiche Completed et deux liens présents sous Download permettent de télécharger le rapport au format PDF ou CSV.


Et voici notre rapport au format PDF.

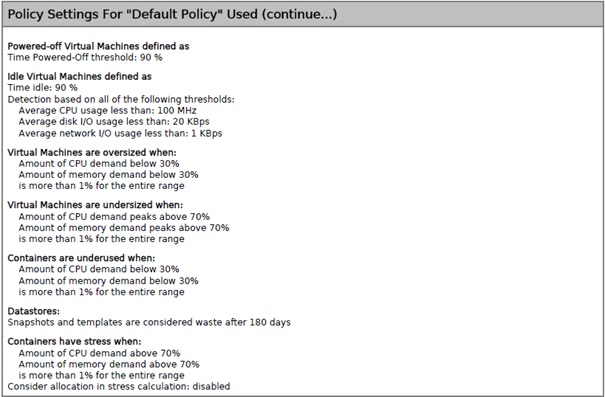
Il est également possible de planifier un rapport pour que sa génération se fasse de manière automatique en cliquant sur New Schedule.

Le password est nécessaire pour tester que l'utilisateur dispose bien des permissions de génération des rapports. Il est ensuite possible de définir les paramètres de génération automatique suivants :
- Start date : date à partir de laquelle sera activée la génération automatique du rapport ;
- Start hour : heure de génération du rapport ;
- Recurrence : hebdomadaire (Weekly) ou mensuelle (Monthly) ;
- Interval : intervalle de génération des rapports ;
- Publishing : possibilité d'envoyer le rapport par e-mail aux adresses spécifiées.

XVII. Remerciements Developpez▲
L'équipe Virtualisation tient à remercier Valentin Pourchet pour la rédaction de ce tutoriel.
Nos remerciements à infosam76 pour sa gabarisation et à ClaudeLELOUP pour sa correction orthographique.
N'hésitez pas à commenter cet article ! Commentez ![]()